


上节我们讲了顺序表的概念,今天我们来讲一下链表
通过顺序表我们知道,当我们要使用顺序表(数据)时,需要开辟一个存储空间,这块存储空间的物理地址像火车车厢一样连续的,
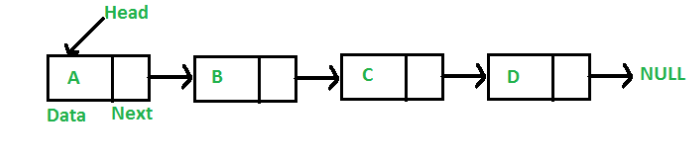
而现在我们所说的链表,顾名思义,就是数据呈链式相连。为了给各个数据块建立“依次排列”的关系,链表给各数据块增设一个指针,每个数据块的指针都指向下一个数据块(在单链表的情况下最后一个数据块的指针一般为null)看似毫无关系的数据块就建立了“依次排列”的关系,也就形成了链表。与顺序表不同,链表里的数据都是随机存储于内存中的,而并不是像顺序表那样在内存里面连续存储的。
接下来的讲解中为了能更好的理解链表,我们依然用火车为例,但这次主角不是火车,而是它行驶的地方-铁轨。(素材来源:http://www.4399.com/flash/96890_4.htm)
链表的查询访问:
我们知道火车不可能平白无故的就在轨道上行驶的,从哪来,往哪去,那么它肯定得要有一个始发站(head),这个head就代表了链表的头,来决定了数据的访问是从哪里开始的,按照刚刚说的由于链表的数据是随机存储在内存里面,如果要访问数据,只能通过每个数据所包含的指针来逐个往下访问,现在通过上图来看,有ABC三个车站,我们看到火车的朝向是从左往右的,因此我们可以将A车站作为是始发站,如果火车要到达任意这三个车站,就需要修建一条能经过这三个站台的轨道,而这指针就如同铁轨一样,是连接的媒介,将三个站台(数据)连接起来。如果我们要去C站台(访问C的数据),只能先到A站台(第一个数据),然后再经过到B站台,最后才能到达C站台,去访问C的数据。

链表添加元素
添加元素分三种情况,第一种在链表头部,链尾添加,第二种,在除了头尾外链的任意位置插入
第一种比较简单的,直接添加元素,如果是在链表的头部,只需把head标识转移到刚刚添加的新元素即可,如果是在链表的尾部添加元素,添加好尾部的新元素后,将null尾节点标识后移即可。


在任意位置任意位置插入元素:
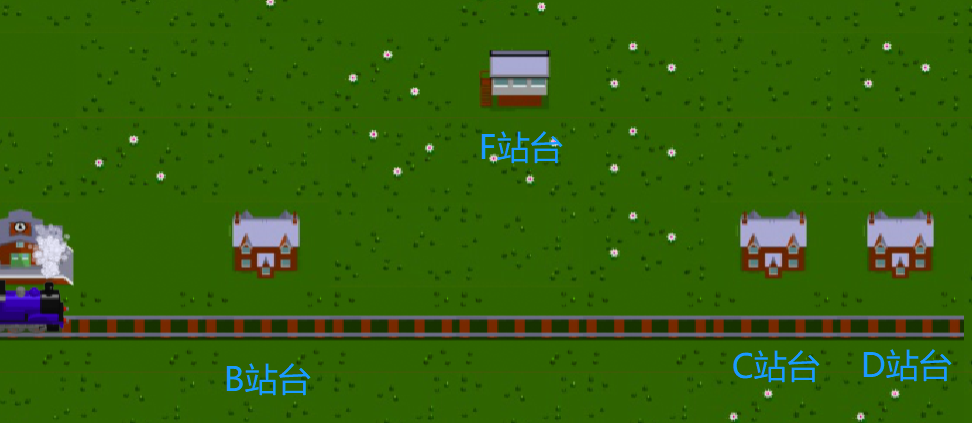
现在F镇上也建了一个站台,但由于他的位置比较特殊,不能像之前几个小镇一样,只用条水平的铁轨就可将彼此连接起来,因此,如果火车要到达F小镇,同时又能抵达到其他站台的话,就只能先将B与C之间的铁轨拆除,将B站台后的铁轨铺去F站台,然后再将F站台的铁轨铺去C站台。

这样子,火车就能即通过F站台,也可以到达接下来的C,D站台了。
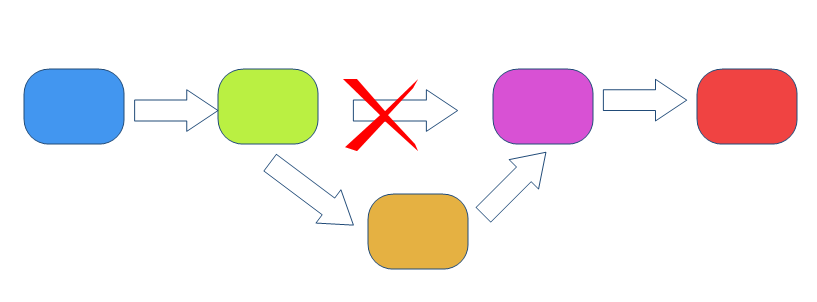
通过上面的例子我们就知道,如果想要在链表中任意位置插入新的元素,那么仅需要两步:
第一步,先找将新元素的下一个节点,指向到原节点所指向的下一个节点
第二步,再将原节点指向下一个节点的指针指向新元素,如下图所示。
 链表删除元素
链表删除元素
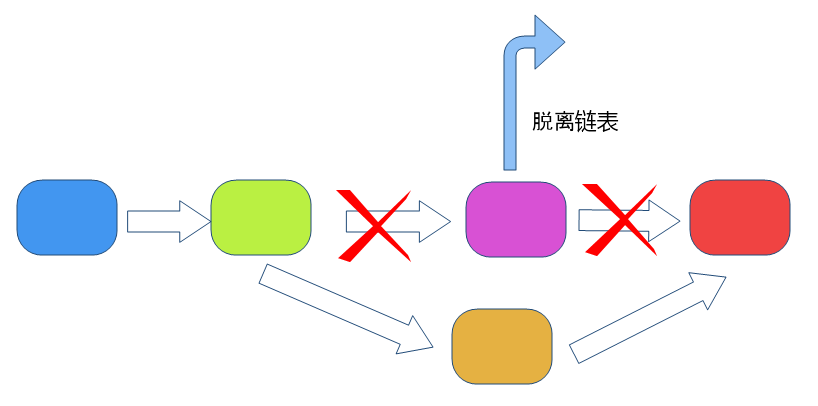
现在我们来讲讲链表是如何实现删除元素的,其实原理还是和在任意位置插入元素类似的。需要三步:
第一步,找到待删除元素前一个元素,
第二步,把待删除元素前一个元素的指针指向待删除元素的后一个元素。
第三步,把删除元素返回,删除元素的下一个元素指针指向NULL,脱离链表。
总结:
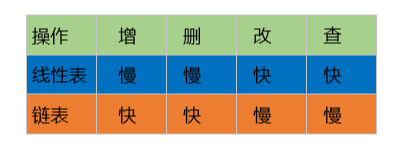
通过上面介绍的关于链表的增删改查,相信大家也对链表有了个大致的认识,我们可以看到链表数据的增加与删除还是属于便捷的,只需对指针进行操作即可,而不用像前一章(线性表)需要将后面的元素往后移来腾出空间安置新元素或者将后面的元素往前补来顶替被删除的元素。但是在查询或修改方面则显得比较麻烦,需要遍历整个链表才能找到目标元素,由此对比两种数据结构可得:
拓展:双向链表
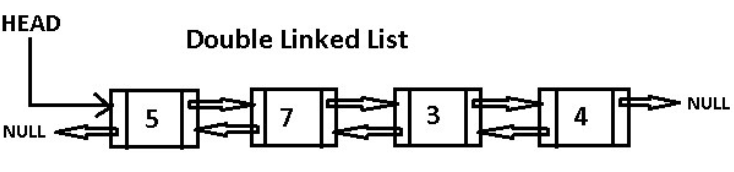
双向链表 中的每个节点(除存储其数据外)都有两个链接。第一个链接指向列表中的上一个节点,第二个链接指向列表中的下一个节点。列表的第一个节点的上一个链接指向NULL,类似地,列表的最后一个节点的下一个节点指向NULL。
这两个链接可帮助我们在向前和向后的方向上遍历列表。但是存储额外的链接需要一些额外的空间。
