

一、双向链表
之前讲过关于单向链表的创建以及插入删除操作.
双向链表有一点不同于单向链表. 单向链表只能是一个顺序方向进行查找, 而双向链表可以对下一个以及上一个进行查找.
这样在某些情况下可以提高计算机的工作效率.
1.1、双向链表的结构
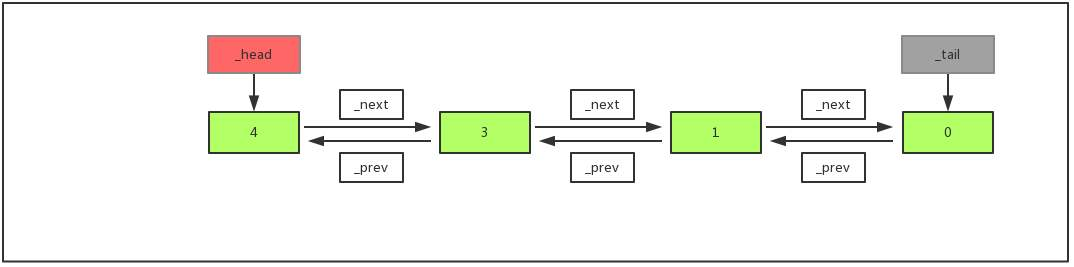
单向链表是包含节点数据以及下一个节点的指针.
双向链表则是包含节点数据以及 下一个和上一个节点的指针. 那么对于单向链表来讲, 就应该是多一个指针指向上一个节点.
typedef int Status;
typedef int LBData;
typedef struct Node {
LBData data;//用来存储一个int数据(具体数据类型根据开发实际情况而定,此处使用int)
struct Node *next;//指向下一个节点的指针
struct Node *prior;//指向上一个节点的指针
} Node;
typedef struct Node * LBList;
1.2、双向链表的创建
这次我们使用双向链表给它加一个头节点, 头节点仅提供第一个节点的指针.
LBList LBInit(LBData data[], unsigned int length) {
LBList lb = (LBList)malloc(sizeof(Node));//开辟一个双向链表的空间, 此时lb为头节点
if (!lb) return 0;//内存申请失败
lb->data = -1;
lb->next = NULL;//初始化
lb->prior = NULL;//初始化
LBList returnLB = lb;//记录一下头节点的地址, 用于返回出去
if (length <= 0) return returnLB;//错误参数 直接返回一个空链表
//根据数据长度进行节点的创建
for (int i = 0; i < length; i++) {
LBList tempList = (LBList)malloc(sizeof(Node));//开辟一个节点
if (!tempList) return 0;//内存申请失败
tempList->data = data[i];//将数据存放进开辟的节点中
tempList->next = NULL;//此时添加的节点是链表的最后一个, 最后一个没有下一个节点
tempList->prior = lb;//被添加的节点的上一个节点也就是当前的节点
lb->next = tempList;//当前节点的下一个节点即为即将添加的节点
lb = tempList;//将当前节点变成添加的节点
}
return returnLB;
}
它与单向链表的不同之处是每次添加一个节点, 必须对添加的节点进行上一个指针与下一个指针的设置.
1.3、双向链表的插入操作
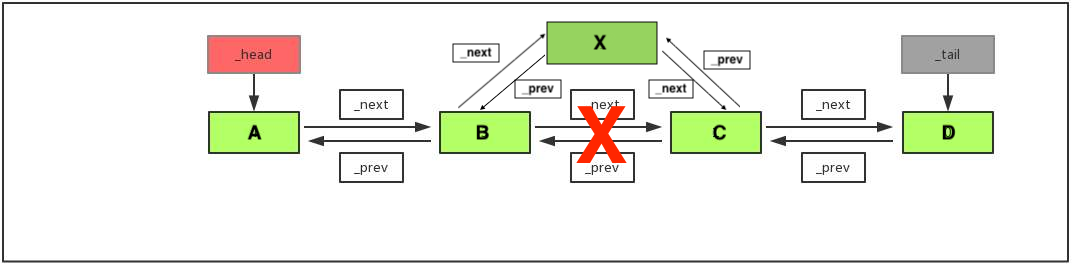
依图分析:
- 新建一个节点X
- 找到节点B
- 节点C的位置放进X的next
- 节点B的位置放进X的prior
- 节点X的位置放进C的prior与B的next
- 特殊情况: 当插入的位置为最后一个位置, 则不需要处理下一个节点
代码实现:
Status LBInsert(LBList *lb, LBData data, unsigned int index) {
if (lb == NULL || (*lb)->next == NULL || index <= 0) return 0; //判断非法参数情况
LBList currentLB = (*lb);
for (int i = 1; i < index && currentLB != NULL; i++, currentLB = currentLB->next);//通过for直接找到要存放的位置的前一个节点, 定位当前节点
if (!currentLB) return 0;//一个非法的位置
LBList insert = (LBList)malloc(sizeof(Node));//创建一个节点用于插入
if (!insert) return 0;
insert->data = data;
insert->next = currentLB->next;//将此节点的下一个节点设置为当前节点的下一个节点
insert->prior = currentLB;//将吃节点的上一个节点设置为当前节点
if (currentLB->next != NULL) {//假如插入的位置为最后一个,即不需要设置它的下一个节点
currentLB->next->prior = insert;//将当前节点的下一个节点的上一个节点设置为即将插入的节点(此时并未插入节点)
}
currentLB->next = insert;//将当前节点的下一个节点设置为即将插入的节点, 插入完成
return 1;
}
1.4、双向链表的删除操作
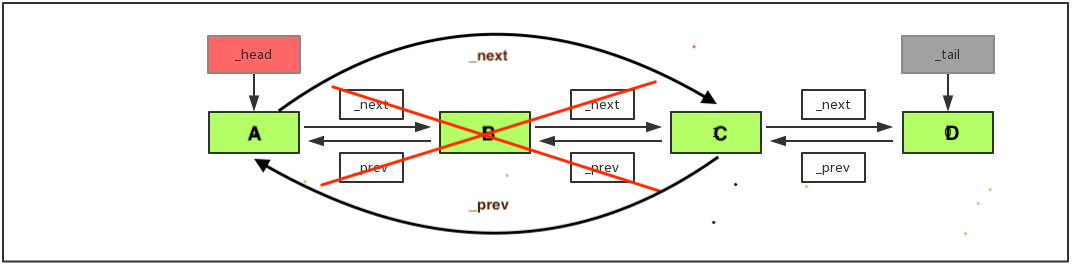
依图分析:
- 找到即将删除的节点B
- 将节点C的上一个节点改为A
- 将节点A的下一个节点改成C
- 释放B节点
- 特殊情况: 当删除当节点为最后一个节点, 则不需要处理被删除的下一个节点
代码实现:
Status LBDelete(LBList *lb, unsigned int index, LBData *data) {// data用于返回被删除的数据, 给外界一个记录
if (lb == NULL || (*lb)->next == NULL || index <= 0) return 0;//非法参数
LBList currentLB = (*lb);//记录当前节点
for (int i = 1; i <= index && currentLB != NULL; i++, currentLB = currentLB->next);//通过for查找到即将删除的节点, 并设置为当前节点
if (!currentLB) return 0;//非法位置
currentLB->prior->next = currentLB->next;//将被删除的节点的上一个节点的下一个节点设置为被删除节点的下一个节点
if (currentLB->next != NULL) {//是否删除的是最后一个节点, 此时无需处理后面的节点
currentLB->next->prior = currentLB->prior;//将被删除节点的下一个节点的上一个节点设置为被删除节点的上一个节点
}
data = ¤tLB->data;//返回被删除的数据给外界
free(currentLB);//释放掉被删除的节点, 删除完成
return 1;
}
二、双向循环链表
上文主要是对双向链表的操作, 双向循环链表是将双向链表的最后一个节点指向第一个节点(非头节点), 达成一个循环.
2.1、双向循环链表的结构
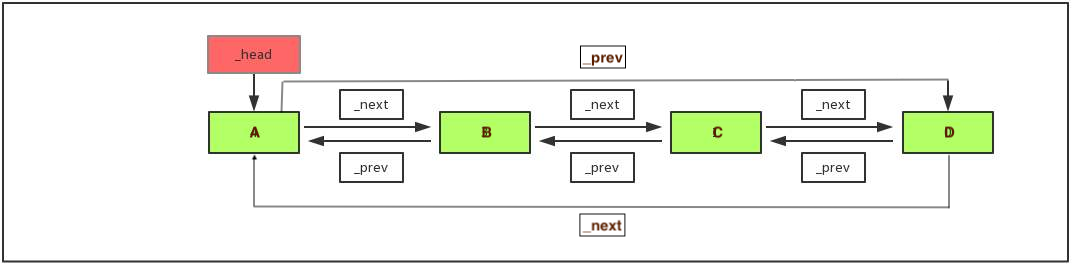
2.2、双向循环链表的创建
在双向链表的基础上, 是要对最后一个节点以及第一个节点进行改进.
代码实现:
LBList LBInit(LBData data[], unsigned int length) {
LBList lb = (LBList)malloc(sizeof(Node));//开辟一个双向链表的空间, 此时lb为头节点
if (!lb) return 0;//内存申请失败
lb->data = -1;
lb->next = NULL;//初始化
lb->prior = NULL;//初始化
LBList returnLB = lb;//记录一下头节点的地址, 用于返回出去
//根据数据长度进行节点的创建
for (int i = 0; i < length; i++) {
LBList tempList = (LBList)malloc(sizeof(Node));//开辟一个节点
if (!tempList) return 0;//内存申请失败
tempList->data = data[i];//将数据存放进开辟的节点中
tempList->next = NULL;//此时添加的节点是链表的最后一个, 最后一个没有下一个节点
tempList->prior = lb;//被添加的节点的上一个节点也就是当前的节点
lb->next = tempList;//当前节点的下一个节点即为即将添加的节点
lb = tempList;//将当前节点变成添加的节点
}
//此时lb为最后一个节点
lb->next = returnLB->next;//将最后节点的下一个设置为第一个节点(头节点的下一个节点)
returnLB->next->prior = lb;//第一个节点的上一个就是最后一个节点
return returnLB;
}
2.3、双向循环链表的插入
双向循环链表的插入与双向链表的插入几乎一致, 唯一的改动之处就是当插入最后一个节点的时候是不需要特殊处理的
相对于双向链表额外的分析:
- 当插入的位置为1的时候, 需要处理头节点
- 因为是循环链表, 获取插入位置的链表的时候需要考虑要插入的位置是否越界
代码实现:
Status LBInsert(LBList *lb, LBData data, unsigned int index) {
if (lb == NULL || (*lb)->next == NULL || index <= 0) return 0; //判断非法参数情况
LBList currentLB = (*lb);
int i;
for (i = 1; i < index && currentLB != NULL && currentLB != (*lb)->next->prior; i++, currentLB = currentLB->next);//通过for直接找到要存放的位置的前一个节点, 定位当前节点, 需要考虑是否超过链表长度
if (!currentLB || i != index) return 0;//一个非法的位置
LBList insert = (LBList)malloc(sizeof(Node));//创建一个节点用于插入
if (!insert) return 0;
insert->data = data;
insert->next = currentLB->next;//将此节点的下一个节点设置为当前节点的下一个节点
if (index == 1) {//当插入位置为第一个的时候处理头节点
insert->prior = (*lb)->next->prior;//插入节点的上一个节点也就是头节点的下一个节点的上一个节点
(*lb)->next->prior->next = insert;//头节点的下一个节点的上一个的下一个节点(最后一个节点的next)设置为插入节点
(*lb)->next = insert;//将头节点的下一个节点设置为插入的节点
} else {//非1位置 正常操作
insert->prior = currentLB;
currentLB->next->prior = insert;
currentLB->next = insert;
}
return 1;
}
2.4、双向循环链表的删除
同样基于双向链表来操作, 需要考虑头节点问题.
相对于双向链表额外的分析:
- 当删除的位置为第一个节点, 需要处理头节点
- 因为是循环链表, 获取删除位置的链表的时候需要考虑要删除的位置是否越界
代码实现:
Status LBDelete(LBList *lb, unsigned int index, LBData *data) {// data用于返回被删除的数据, 给外界一个记录
if (lb == NULL || (*lb)->next == NULL || index <= 0) return 0;//非法参数
LBList currentLB = (*lb);//记录当前节点
int i;
for (i = 0; i < index && currentLB != NULL && currentLB != (*lb)->next->prior; i++, currentLB = currentLB->next);//通过for查找到即将删除的节点, 并设置为当前节点, 需要考虑是否越界
if (!currentLB || i != index) return 0;//非法位置
if (index == 1) {//当删除当为第一个节点
LBList firstNode = currentLB;//得到首节点
LBList lastNode = currentLB->prior;//得到最后一个节点
lastNode->next = firstNode->next;//最后一个节点当下一个节点为首节点的下一个节点
firstNode->next->prior = lastNode;//首节点的下一个节点的上一个节点为最后一个节点
(*lb)->next = firstNode->next;//将链表的头节点设置为首节点的下一个节点
} else {//其他位置正常操作
currentLB->prior->next = currentLB->next;//将被删除节点的上一个节点的下一个节点设置为被删除节点的下一个节点
currentLB->next->prior = currentLB->prior;//将被删除节点的下一个节点的上一个节点设置为被删除节点的上一个节点
}
data = ¤tLB->data;//返回被删除的数据给外界
free(currentLB);//释放掉被删除的节点, 删除完成
return 1;
}
三、总结
双向链表相对于单向链表多了一个指向上一个节点的指针, 这样的好处会使链表更加的灵活.
无论是逆向查找还是正向查找都可以进行. 而且定义了一个头节点的data可以用来存放链表的长度. 根据需要对链表进行操作的位置来决定对链表进行逆向还是正向查找.
相对的, 因为多加了一个指向上一个节点的指针, 对链表进行操作需要多进行一个设置上个节点的操作, 考虑的情况要稍微比单向复杂一点点.
