

简介
在这篇文章中,我们将通过使用Python的Sklearn(又名Scikit Learn)库实现SVM(支持向量机)算法的教程。首先,我们将简要地了解SVM分类器的工作。然后,我们将看到一个带有数据集的端到端项目,以说明一个使用Sklearn模块和GridsearchCV寻找最佳超参数的SVM的例子。
什么是支持向量机(SVM)?
支持向量机算法,更好地称为SVM,是一种有监督的机器学习算法,可用于解决分类和回归问题。
SVM利用极端数据点(向量)来生成超平面,这些向量/数据点被称为支持向量。SVM算法的主要目标是创建一个具有最大余量的最佳超平面,该超平面可以将一个n维空间分成不同的类别。
下图说明了SVM的各个方面:

- 超平面:这是在n维空间中分离两个类别的决策边界。我们的数据集中存在的特征数量决定了超平面的数量。假设我们只有两个特征,那么超平面将是一条直线,在有三个特征的情况下,我们得到一个二维平面。
- 支持矢量:这些数据点会影响超平面的定位。
- 边际:向量/数据点与超平面之间的距离被称为边距。
- 最大余量:具有最大余量的超平面被称为最佳超平面。
Python Sklearn中的SVM实例
为了在Python中创建一个SVM分类器,Scikit-Learn包中有一个函数svm.SVC(),使用起来非常方便。
让我们通过下面一个端到端的项目例子来了解它的实现,我们将使用医疗数据来预测人是否有心脏病。
i) 导入所需的库
我们首先导入建立我们的模型所需的库。
在[2]中:
#Import python packages
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split # Import train_test_split function
from sklearn import svm #Import svm model
from sklearn import metrics #Import scikit-learn metrics module for accuracy calculation
from sklearn.metrics import confusion_matrix,roc_curve,roc_auc_score,accuracy_score, plot_confusion_matrix,classification_report
ii) 加载数据
接下来,我们将CSV文件中的数据集加载到Pandas数据框中,并通过使用数据框的head()函数来验证数据是否正常加载。
在[3]中:
df = pd.read_csv(r"C:\Users\Veer Kumar\Downloads\heart.csv")
在[4]中:
df.head()
Out[4]:
| 年龄 | 性别 | cp | 胎心率(trestbps) | chol | fbs | 补钙 | 钍 | ǞǞǞ | 老峰 | 坡度 | ca | thal | 目标 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 63 | 1 | 3 | 145 | 233 | 1 | 0 | 150 | 0 | 2.3 | 0 | 0 | 1 | 1 |
| 1 | 37 | 1 | 2 | 130 | 250 | 0 | 1 | 187 | 0 | 3.5 | 0 | 0 | 2 | 1 |
| 2 | 41 | 0 | 1 | 130 | 204 | 0 | 0 | 172 | 0 | 1.4 | 2 | 0 | 2 | 1 |
| 3 | 56 | 1 | 1 | 120 | 236 | 0 | 1 | 178 | 0 | 0.8 | 2 | 0 | 2 | 1 |
| 4 | 57 | 0 | 0 | 120 | 354 | 0 | 1 | 163 | 1 | 0.6 | 2 | 0 | 2 | 1 |
三)数据集的细节
我们的心脏数据集有303行和14列,数据集中所有属性的意义如下
- 年龄:该人的年龄,以岁为单位
- 性别:该人的性别(1=男性,0=女性)。
- cp:所经历的胸痛(值1:典型心绞痛,值2:非典型心绞痛,值3:非心绞痛,值4:无症状)
- trestbps:该人的静息血压(入院时为毫米汞柱) chol: 该人的胆固醇测量值,单位为毫克/分升
- fbs:该人的空腹血糖(>120毫克/分升,1=真;0=假)。
- restecg:静止心电图测量(0=正常,1=有ST-T波异常,2=按Estes标准显示可能或明确的左心室肥大)
- 塔拉赫:该人达到的最大心率
- exang:运动诱发的心绞痛(1=是;0=否)
- oldpeak。运动诱发的ST段压低相对于静止状态("ST "与心电图上的位置有关。 更多信息请见这里)
- 斜率:运动时ST段峰值的斜率(值1:上斜,值2:平坦,值3:下斜)。
- ca:主要血管的数量(0-3)
- thal: 一种叫做地中海贫血的血液疾病(3=正常;6=固定缺陷;7=可逆缺陷)
- target: 心脏病(0=没有,1=有)
四)获得数据集的汇总统计
我们使用pandas dataframes的describe函数()来快速获得数据集的统计信息。
In[5]:
df.describe()
Out[5]:
| 年龄 | 性别 | cp | 胎心率(trestbps) | chol | fbs | 补钙 | 钍 | ǞǞǞ | 老峰 | 坡度 | ca | thal | 目标 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 计数 | 303.000000 | 303.000000 | 303.000000 | 303.000000 | 303.000000 | 303.000000 | 303.000000 | 303.000000 | 303.000000 | 303.000000 | 303.000000 | 303.000000 | 303.000000 | 303.000000 |
| 平均值 | 54.366337 | 0.683168 | 0.966997 | 131.623762 | 246.264026 | 0.148515 | 0.528053 | 149.646865 | 0.326733 | 1.039604 | 1.399340 | 0.729373 | 2.313531 | 0.544554 |
| 标准 | 9.082101 | 0.466011 | 1.032052 | 17.538143 | 51.830751 | 0.356198 | 0.525860 | 22.905161 | 0.469794 | 1.161075 | 0.616226 | 1.022606 | 0.612277 | 0.498835 |
| 负数 | 29.000000 | 0.000000 | 0.000000 | 94.000000 | 126.000000 | 0.000000 | 0.000000 | 71.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 47.500000 | 0.000000 | 0.000000 | 120.000000 | 211.000000 | 0.000000 | 0.000000 | 133.500000 | 0.000000 | 0.000000 | 1.000000 | 0.000000 | 2.000000 | 0.000000 |
| 50% | 55.000000 | 1.000000 | 1.000000 | 130.000000 | 240.000000 | 0.000000 | 1.000000 | 153.000000 | 0.000000 | 0.800000 | 1.000000 | 0.000000 | 2.000000 | 1.000000 |
| 75% | 61.000000 | 1.000000 | 2.000000 | 140.000000 | 274.500000 | 0.000000 | 1.000000 | 166.000000 | 1.000000 | 1.600000 | 2.000000 | 1.000000 | 3.000000 | 1.000000 |
| 最大 | 77.000000 | 1.000000 | 3.000000 | 200.000000 | 564.000000 | 1.000000 | 2.000000 | 202.000000 | 1.000000 | 6.200000 | 2.000000 | 4.000000 | 3.000000 | 1.000000 |
v) 数据可视化
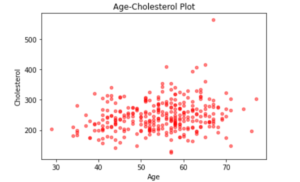
在这里,我们用散点图来直观地显示病人的年龄和他们的胆固醇水平之间的关系。
该图表明,与其他年龄组相比,60至70岁年龄组的胆固醇水平略高。除此之外,我们还推断,40岁以下的人的胆固醇水平大多低于300水平。
在[7]:
df.plot(kind = 'scatter',x = 'age', y = 'chol',alpha = 0.5, color = 'red')
plt.xlabel('Age')
plt.ylabel('Cholesterol')
plt.title('Age-Cholesterol Plot')
Out[7]:
Text(0.5, 1.0, 'Age-Cholesterol Plot')
vi) 数据预处理
在这里,我们将分离独立特征和目标标签。
在[8]中:
#Separate Feature and Target Matrix
x = df.drop('target',axis = 1)
y = df.target
vi) 将数据集分割成训练集和测试集
我们在train_test_split()函数的帮助下将训练集和测试集分开。
在[9]中:
# Split dataset into training set and test set
# 70% training and 30% test
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2,random_state=100)
vi) 创建和训练SVM分类器
在这里,我们创建了一个SVM分类器,将使用训练数据进行训练。由于我们的数据集是有限的,K折交叉验证是一个很好的方法来估计我们模型的性能。在这里,我们使用GridSearchCV模块,以测试一些可以优化我们模型性能的参数组合。对于超参数的调整,我们有3个参数需要考虑。
- Kernel=rbf(径向基函数):核函数用于将原始数据集(线性/非线性)映射到一个高维空间,以期使其成为一个线性数据集。
- C参数:它是SVM中用来控制误差的一个超参数。它作为一个惩罚参数,C的小值将导致超平面分离的更大余量。如果我们不希望我们的训练点被错误分类,那么我们就选择一个大的C值,这将导致一个较小的边际分离平面,但它可能导致一个过拟合问题,即模型在训练数据上可能不能很好地概括。
- 伽马参数:这将决定决策边界的曲率,伽玛越大,决策边界的曲率就越大。
在[11]:
from sklearn.model_selection import GridSearchCV
#Create a svm Classifier and hyper parameter tuning
ml = svm.SVC()
# defining parameter range
param_grid = {'C': [ 1, 10, 100, 1000,10000],
'gamma': [1,0.1,0.01,0.001,0.0001],
'kernel': ['rbf']}
grid = GridSearchCV(ml, param_grid, refit = True, verbose = 1,cv=15)
# fitting the model for grid search
grid_search=grid.fit(x_train, y_train)
出[11]:
Fitting 15 folds for each of 25 candidates, totalling 375 fits
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 375 out of 375 | elapsed: 11.7s finished
vii)取出最佳超参数
训练完成后,我们可以从GridsearchCV中获取最佳的超参数和相应的准确度分数。
我们可以看到,C=100,gamma=0.0001的值产生了最佳结果,准确率为81.00%。
在[12]:
print(grid_search.best_params_)
Out [12]:
{'C': 100, 'gamma': 0.0001, 'kernel': 'rbf'}
在[13]中:
accuracy = grid_search.best_score_ *100
print("Accuracy for our training dataset with tuning is : {:.2f}%".format(accuracy) )
出[13]:
Accuracy for our training dataset with tuning is : 81.00%
viii)寻找测试模型的准确性
测试模型的准确性将告诉我们我们的模型在训练数据上的泛化程度,在预测未见过的数据值的基础上。我们可以看到,在测试数据上,我们的SVM分类器的准确率为80.33%,确实泛化得不错。
在[14]:
y_test_hat=grid.predict(x_test)
test_accuracy=accuracy_score(y_test,y_test_hat)*100
test_accuracy
print("Accuracy for our testing dataset with tuning is : {:.2f}%".format(test_accuracy) )
出[14]:
Accuracy for our testing dataset with tuning is : 80.33%
ix) 绘制混淆矩阵
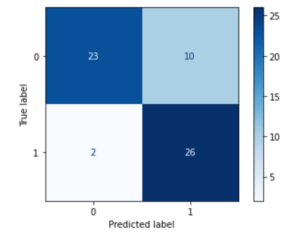
最后,我们用测试数据来评估模型,用混淆矩阵来找出真阳性、真阴性、假阳性和假阴性的数量。
在[15]:
confusion_matrix(y_test,y_test_hat)
disp=plot_confusion_matrix(grid, x_test, y_test,cmap=plt.cm.Blues)
出[15]:
-
23名患者被预测为患有心脏病,预测是正确的(真-阳性)
-
26名患者被预测为不会有心脏病,预测是正确的(真阴性)
-
10名患者被预测为患有心脏病,但预测是错误的(假阳性)
-
2名患者被预测为不会有心脏病,但预测结果是错误的(假阴性)
-
还可以阅读-机器学习中的过拟合和欠拟合 - 初学者的动画指南
结论
我们希望你喜欢我们的教程,现在能更好地理解如何在Python中使用Sklearn(Scikit Learn)实现支持向量机(SVM)。在这里,我们已经说明了一个端到端的例子,即使用数据集建立一个SVM模型,以便利用Sklearn svm.SVC()模块来预测心脏病。
